

translation. (Photo ... VIEW ORIGINAL
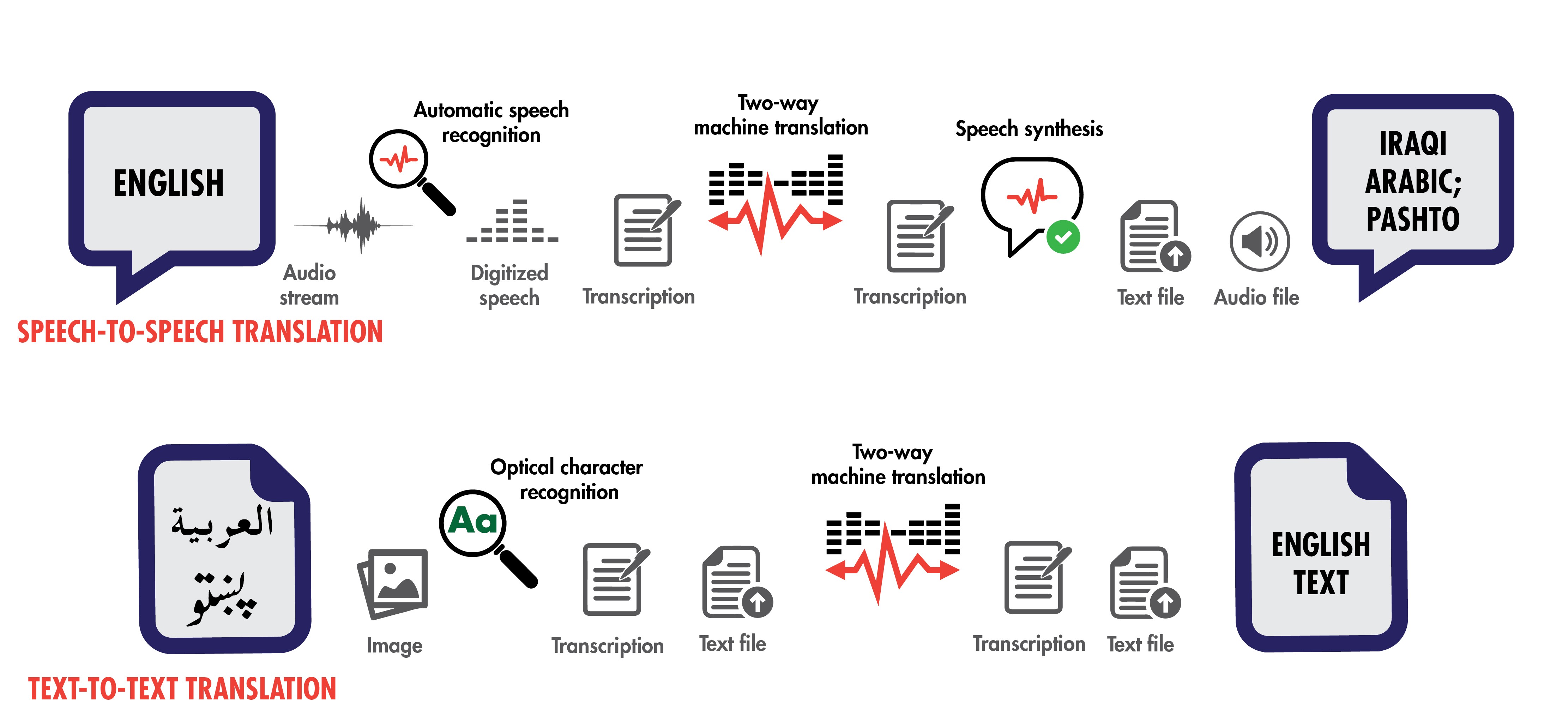
Today's more expeditionary Army needs interpreters and linguists, but they are expensive to train and always in short supply. In another case of science fiction becoming science fact, the Army has created a partial solution to the language barrier: the Machine Foreign Language Translation System (MFLTS). Right now, MFLTS consists of two apps, one for real-time, two-way, speech-to-speech translation and one for text-to-text translation of electronic documents, webpages and social media.
Each application has two main parts. One is the core app, which handles all of the interaction between the user and the underlying tools. You could call it the "work manager," because it helps the other parts of the translation system "talk" to one another.
The second important part is the language pack, which contains language-specific, machine-trained models and dictionaries needed to make translations. The language packs are modular plug-ins that users can install and remove to do the needed translation work in the user's environment.
MACHINE LEARNING 101
The machine learning that supports the developments in human-language technology underpinning MFLTS draws on computer science, neuroscience, and artificial-intelligence research and theory on ways to enable a computer to learn or do something on its own without explicit programming by a human to do so. Without machine learning, MFLTS could be only as good as the humans who feed the system data and statistical information; thus there would be a built-in limit to how well it could translate.
Artificial neural networks, based loosely on the human brain's structure, are what make machine learning possible and offer the potential to create truly artificial intelligence sometime in the future. The networks that power machine intelligence learn in a very humanlike way: as Gideon Lewis-Kraus wrote in a Dec. 14, 2016, New York Times Magazine article about Google's work on machine learning, they "acquaint themselves with the world via trial and error, as toddlers do."
The way that MFLTS is put together, these two parts are equally involved in translating. When a Soldier starts a translation session, the manager part of the app starts a session between the Soldier and the language pack's translation tools that the Soldier will need to get the job done. During translation, the app captures input, manages processes and provides the translation to the user.
MAKING MAGIC
The real magic of MFLTS lives deep within the language packs, where science and art come together to enable software to hear, understand and interpret as much like a human linguist as possible.
Inside language packs are two or more language components that contain what are called "probabilistic models," developed by software scientists and engineers using advanced machine learning techniques. An example of a probabilistic model is the way a smartphone "guesses" what you are typing before you've finished.
Of course, translation is much more complex, so these machine learning techniques include processing large volumes of highly structured, annotated language data to develop models that recognize the relationships among the elements of speech. For the speech app, these language components are the automated speech recognizer, the machine-translation engine and the text-to-speech speech synthesizer.
A microphone captures speech, and the automated speech recognizer turns it into text data by using a probabilistic model that finds the most likely match between the speech that's been converted to text and what the machine has learned. After the speech is converted to text, the text shows on the display so the user can decide whether it is correct. This is how the Google Assistant, Apple's Siri and others "understand" you when you ask them to find the next nearest gas station, or when you ask Amazon's Alexa to play a specific song from your music library.
The automated speech recognizer doesn't complete all of the requested translation task; its job is done when it passes the recognized speech in text to the next process, machine translation.
CORE PROCESSES
Inside a language pack, the machine-translation engine is the component that performs the "magic" of the actual translation. Like the automated speech recognizer, a machine-translation engine uses probabilistic models that are trained using dual-language sets of data developed with the expertise of people fluent in both languages in a language pair--for example, English and Arabic.
Not surprisingly, developing machine-translation engines for unusual pairs of language is often very labor-intensive and expensive because of the scarcity of data and linguists proficient in both languages. As developers of the automated speech recognizer's model have done, engineers and scientists who are creating machine-translation models rely on techniques for model training that are a combination of science and art.
Machine translation probabilistic models find the best match between the source and target languages and, like the automated speech recognizer, then provide text output in the target language to a speech synthesizer and to a display, using the target language's character set.
Finally, for the speech app, the text-to-speech language part of the app is a synthesis program that produces audible speech in the target language. Like the automated speech recognizer and machine translation, the text-to-speech component relies on extensively trained speech-synthesizing models that provide the text-to-speech conversion.
After receiving the text from the machine-translation engine, the text-to-speech function converts the text into spoken language by putting together words or phrases from recorded speech of the target language. MFLTS then plays the text-to-speech content on the internal or external speaker of, typically, a smartphone.
Working together, these language components are the "brain" of MFLTS, appearing to hear, understand and translate English into another language.
Let's say that a Soldier has just translated speech from an Arabic-speaking local. Now the Soldier needs to reverse the process, translating from English to Arabic. That's no problem; it's why the MFLTS language packs always travel in pairs.
FROM TEXT TO TEXT
With the MFLTS text translation app, Soldiers can translate text-based media, such as webpages and posts on Twitter and other social media. Like the speech app's machine-translation engines, the text-to-text engine is trained on a large body of language data.
Text translation is typically quick and highly accurate. Because it does not have to recognize speech, which can vary a lot between individuals, or synthesize it, there are fewer sources of errors in the final translation.
CONCLUSION
For many Soldiers, the MFLTS speech app may be the best alternative to a human linguist, especially if there isn't one around. The Army's MFLTS program intends to leverage major advances in language translation technology and machine learning to provide a cost-effective capability that will enable Soldiers to break through the language barriers that the expeditionary Army will continue to encounter.
MFLTS has been in service since December 2016, when it was first fielded on the smartphone-like Nett Warrior devices used by the 1st Brigade, 82nd Airborne Division. The system is also being used in support of Operation Inherent Resolve in Iraq.
Based on a 2017 congressional increase in research, development, testing and evaluation funding for the Army MFLTS program, the MFLTS Product Office anticipates adding several languages to the portfolio, potentially to include Russian, Dari, Urdu, Farsi and Korean, within the next 12 to 18 months. The product office is assigned to the project manager for Distributed Common Ground System -- Army in the Program Executive Office for Intelligence, Electronic Warfare and Sensors.
For more information about the MFLTS program, go to https://peoiews.army.mil/dcgsa.
MR. MICHAEL DONEY is the product director for MFLTS at Fort Belvoir, Virginia. He holds an M.S. in engineering management from George Washington University and a B.S. in civil engineering from Virginia Tech. He is Level III certified in program management and in engineering and is a 2014 graduate of Defense Acquisition University's Program Manager's Course. He has been a member of the Army Acquisition Corps since 2004.
DR. CHRISTINA BATES provides contract support to various organizations within the Army acquisition and research, development and engineering communities as a strategic analyst, planner and strategic communications expert. Bates holds a Ph.D. in communication with an emphasis on organizational communication and behavior from Arizona State University; a J.D. from Boston University; an M.S. in mass communication, with distinction, from Boston University; and a B.A. cumlaude, in sociology and communication from Boston College. She is a Lean Six Sigma Master Black Belt.
MR. TRACY BLOCKER is the MFLTS product office representative to the U.S. Army Training and Doctrine Command at Fort Huachuca, Arizona. He holds a B.A. in English from Georgia Southern University and is a graduate of the Postgraduate Intelligence Program of the Joint Military Intelligence College (now the National Intelligence University). He is a retired Army military intelligence officer who served in tactical and operational units.
This article is published in the October -- December 2017 Army AL&T magazine.
Social Sharing